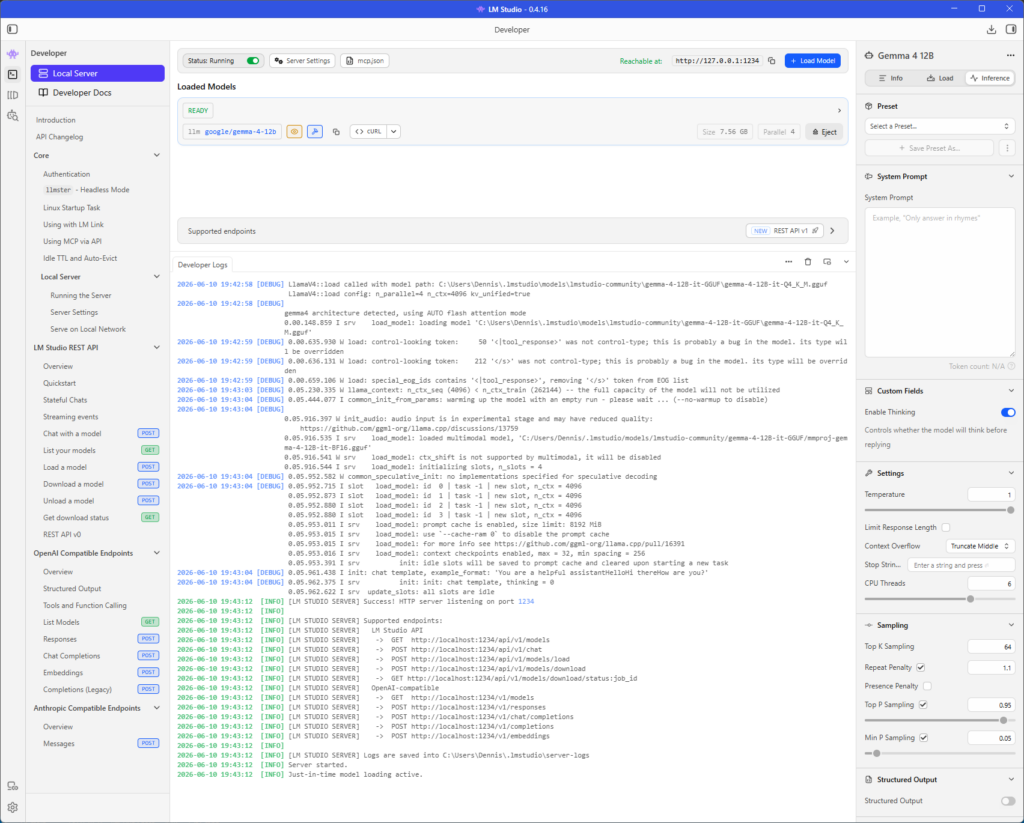
Ich nutze schon länger SearXNG und bin bei selfh.st über degoog gestolpert. Von der Idee her dasselbe, gefühlt aber etwas moderner und schicker. Auch hier können verschiedene Suchmaschinen eingebunden werden und die Ergebnisse werden dann aggregiert. Dazu gibt es auch noch Plugins, z.B. für Wetter oder OpenStreetMap.
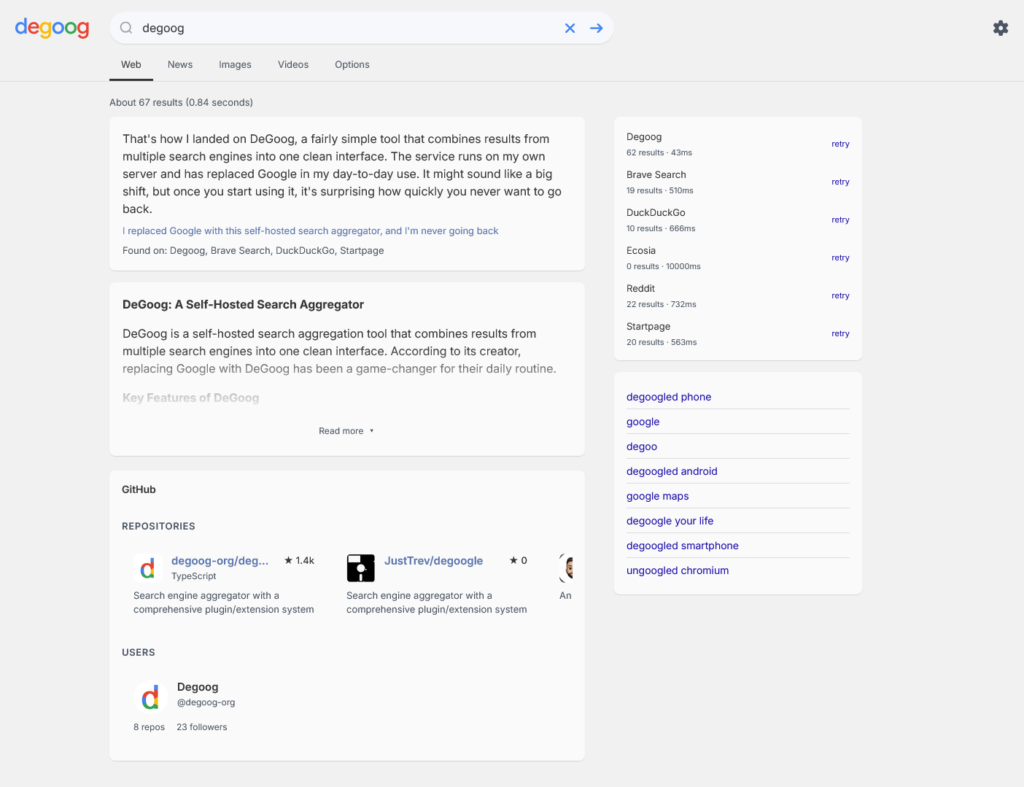
Und hier ein Suchergebnis meiner SearXNG Instanz:
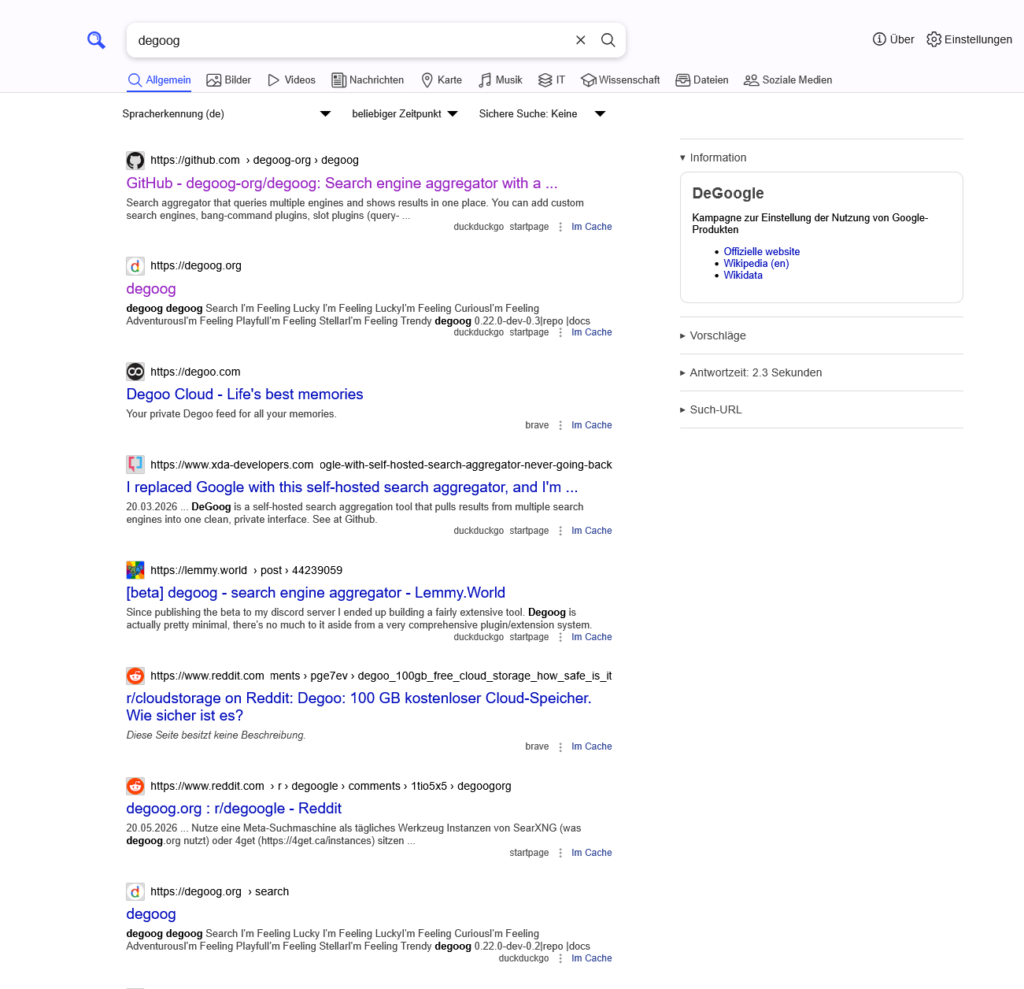
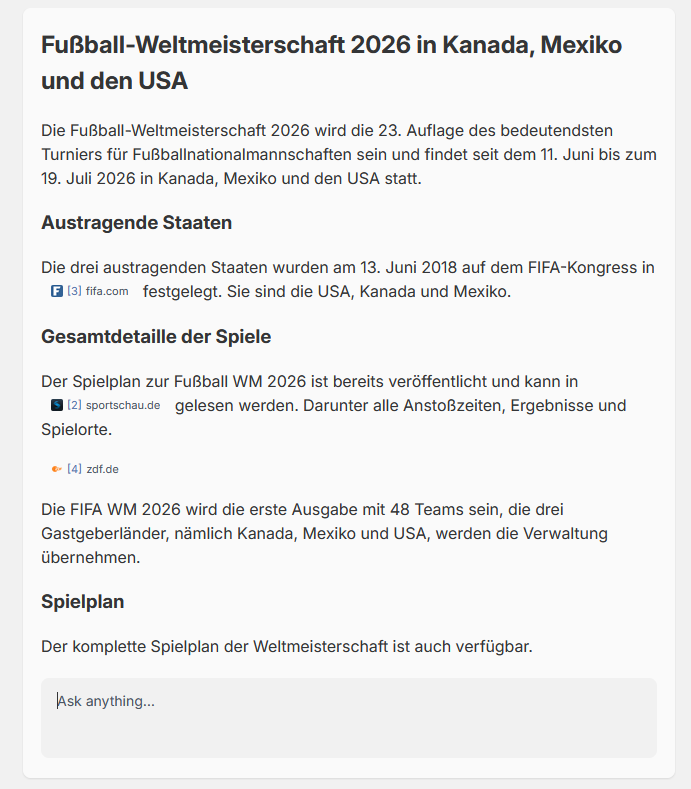
Ein nettes Feature ist das Plugin AI Summary. Mit einem (lokalen) LLM lassen sich Zusammenfassungen zur Suche generieren. Ich hab das mal mit llama3.2 ausprobiert, weil es sehr schnell Antworten erzeugt.
Und eingerichtet ist degoog auch innerhalb von wenigen Minuten mit Docker Compose.