Voraussetzung: LM Studio läuft und hat Gemma-4-12B geladen, zusätzlich ist der Server Mode aktiviert.
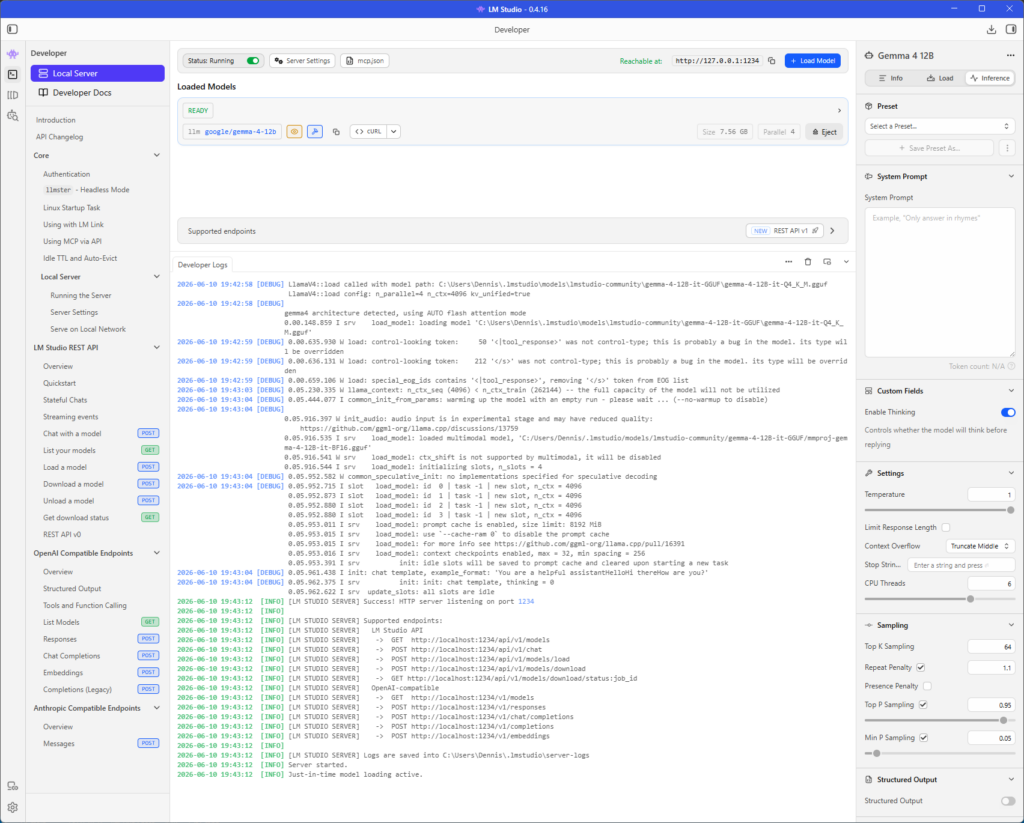
In VS Code im Chat auf die Modellauswahl und dann Manage Language Models.
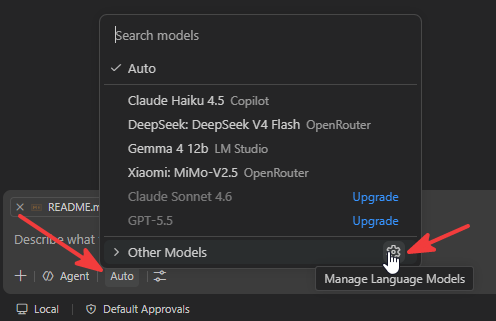
Nun die JSON Config öffnen.
Und folgendes dem vorhandenen JSON hinzufügen:
{
"name":"LM Studio",
"vendor":"customendpoint",
"apiKey":"not-needed",
"models":[
{
"id":"google/gemma-4-12b",
"name":"Gemma 4 12b",
"url":"http://localhost:1234/v1/chat/completions",
"toolCalling":true
}
]
}Wichtig sind vor allem die ID und die URL.
Dazu habe ich dann noch für meine Radeon RX 9070 XT mit leider nur 16 GB RAM noch ein paar Einstellungen in LM Studio angepasst. Das wird vermutlich für andere GPU anders aussehen.
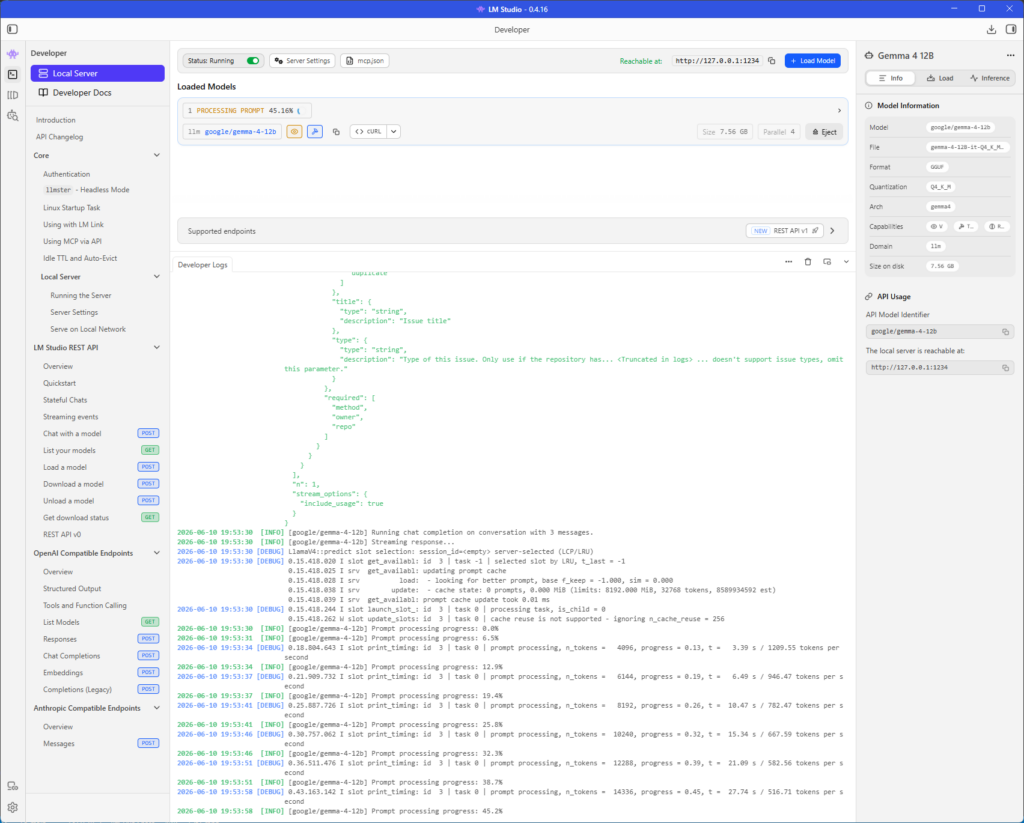
Unter Load habe ich den Context auf 32768 gesetzt, default sind nur 4096. Viel zu wenig.
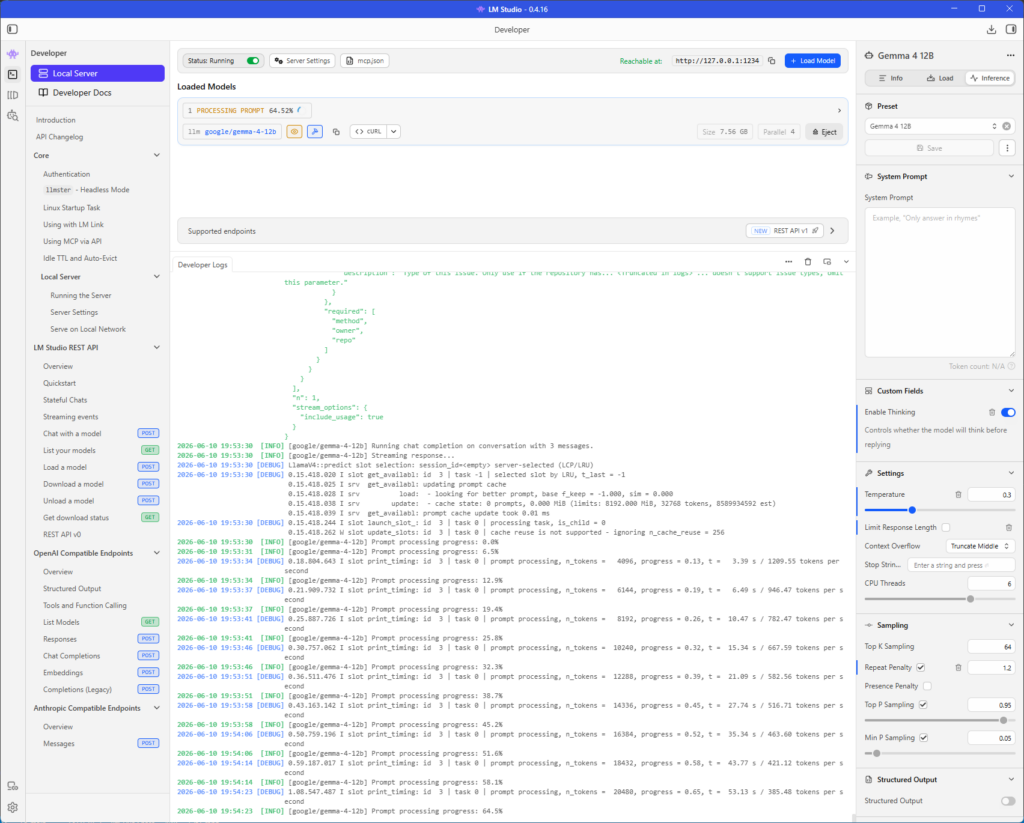
Unter Inference muss Enable Thinking aktiviert sein, die Temperature habe ich auf 0.3 reduziert und die Repeat Penalty auf 1.2 gesetzt.
Und das hier ist dann z.B. ein Ergebnis nach ca. 3 Minuten.
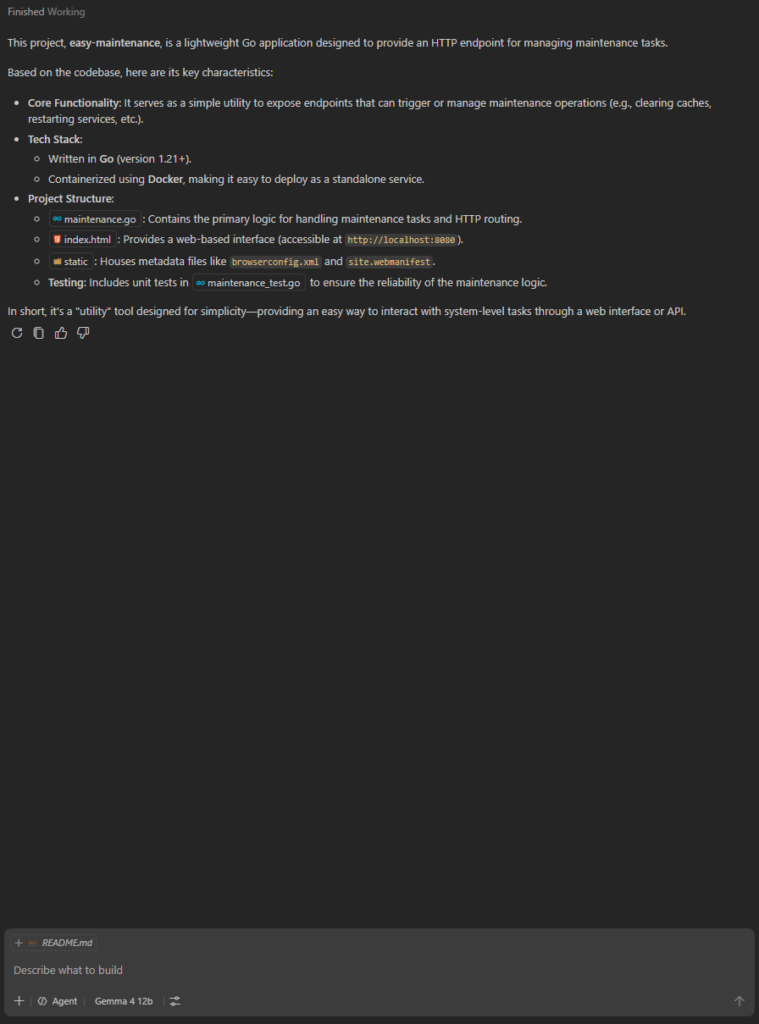
Fazit: Technisch geht das. Macht das mit so einer kleinen GPU Spaß? Nicht wirklich… Dann doch lieber ein paar € in OpenRouter einwerfen und auf Deep Seek V4 Flash oder MiMo-V2.5 setzen. Für private Projekt ist das mehr als ausreichend, vor allem schneller, stabiler und weniger frustrierend.
Sei der Erste der einen Kommentar abgibt